Abstract
Text-to-motion generation has recently garnered significant research interest, primarily focusing on generating human motion sequences in blank backgrounds. However, human motions commonly occur within diverse 3D scenes, which has prompted exploration into scene-aware text-to-motion generation methods. Yet, despite notable progress, existing scene-aware methods often rely on large-scale ground-truth motion sequences in diverse 3D scenes, which poses practical challenges due to the expensive cost. To mitigate this challenge, we are the first to propose a Training-free Scene-aware Text-to-Motion framework, dubbed as TSTMotion, that efficiently empowers pre-trained blank-background motion generators with the scene-aware capability. Specifically, conditioned on the given 3D scene and text description, we adopt foundation models together to reason, predict and validate a scene-aware motion guidance. Then, the motion guidance is incorporated into the blank-background motion generators with two modifications, resulting in scene-aware text-driven motion sequences. Extensive experiments demonstrate the efficacy and generalizability of our proposed framework.
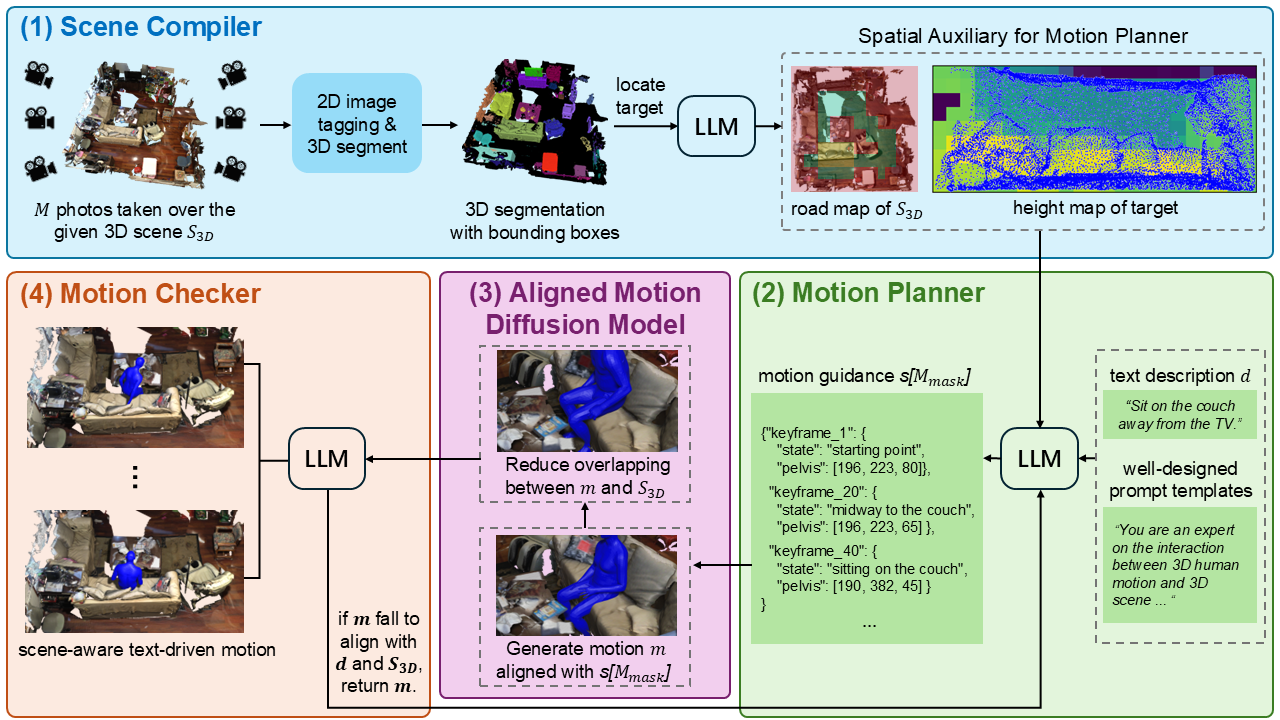 An overview of our proposed training-free TSTMotion framework for the given text $d$ and 3D scene $S_{3D}$. At first, the Scene Compiler extracts the spatial auxiliary in the $S_{3D}$. Based on the spatial auxiliary, the Motion Planner incorporates the text description and well-designed prompt templates to infer the motion guidance $s[M_{mask}]$. Equipped with the $s[M_{mask}]$, the Aligned Motion Diffusion Model predicts initial scene-aware text-driven motion sequences $m$ with two training-free modifications. Finally, the Motion Checker is applied to iteratively refine and generate final $m$ to better align with the $d$ and $S_{3D}$.
An overview of our proposed training-free TSTMotion framework for the given text $d$ and 3D scene $S_{3D}$. At first, the Scene Compiler extracts the spatial auxiliary in the $S_{3D}$. Based on the spatial auxiliary, the Motion Planner incorporates the text description and well-designed prompt templates to infer the motion guidance $s[M_{mask}]$. Equipped with the $s[M_{mask}]$, the Aligned Motion Diffusion Model predicts initial scene-aware text-driven motion sequences $m$ with two training-free modifications. Finally, the Motion Checker is applied to iteratively refine and generate final $m$ to better align with the $d$ and $S_{3D}$.













 Demonstration of the motion guidance output by the Motion Planner given different text prompts.
Demonstration of the motion guidance output by the Motion Planner given different text prompts.